Google 繼推出文本生成圖像 AI 工具「Imagen」,公開了一系列 Imagen 生成的圖片後,早前正式有限度地亮相並公開給大眾。Google 產品管理高級總監 Josh Woodward 表示,將會以有限的方式將 Imagen 新增到 Google 的 AI Test Kitchen 應用程式中,主要用作技術團隊收集意見,從而了解人工智能模型的能力和局限。
Google 繼推出文本生成圖像 AI 工具「Imagen」,公開了一系列 Imagen 生成的圖片後,早前正式有限度地亮相並公開給大眾。Google 產品管理高級總監 Josh Woodward 表示,將會以有限的方式將 Imagen 新增到 Google 的 AI Test Kitchen 應用程式中,主要用作技術團隊收集意見,從而了解人工智能模型的能力和局限。
Imagen 是什麼?
Imagen 是文字生成圖像的擴散模型(Diffusion Model),可以解析用家輸入的文字,深度理解文字意義,然後輸出像相片般的寫實圖像。Imagen 由 Google 旗下深度學習與人工智慧科研專案團隊 Google Brain 負責,建於大型 Transformer 語言模型之上,因此擁有強大的文字理解能力,透過擴散模型便能生成高畫質的圖像。
如何與 Imagen 互動?
Imagen 怎麼用?目前為止,有兩種方式與 Imagen 互動,包括:City Dreamer 和 Wobble。
City Dreamer:這與 SimCity 中看到畫像類似,用戶可以在這模式中輸入圍繞城市設計的不同元素,例如南瓜、牛仔布或顏色等。Imagen 便會隨之創建與之相乎的城鎮廣場、公寓樓、機場等不同建築物和土地。
Wobble:這與 Pixar 中的 Monsters 類似,用戶現要創作一個小怪物,可以 可以先選擇粘土、毛氈、杏仁糖、橡膠不同材質,然後選擇衣服,Imagen 模型便會根據文字生成小怪物。你還可為它起名字,戳戳小怪物讓它動起來。
Imagen 與 DALL-E 2 比較
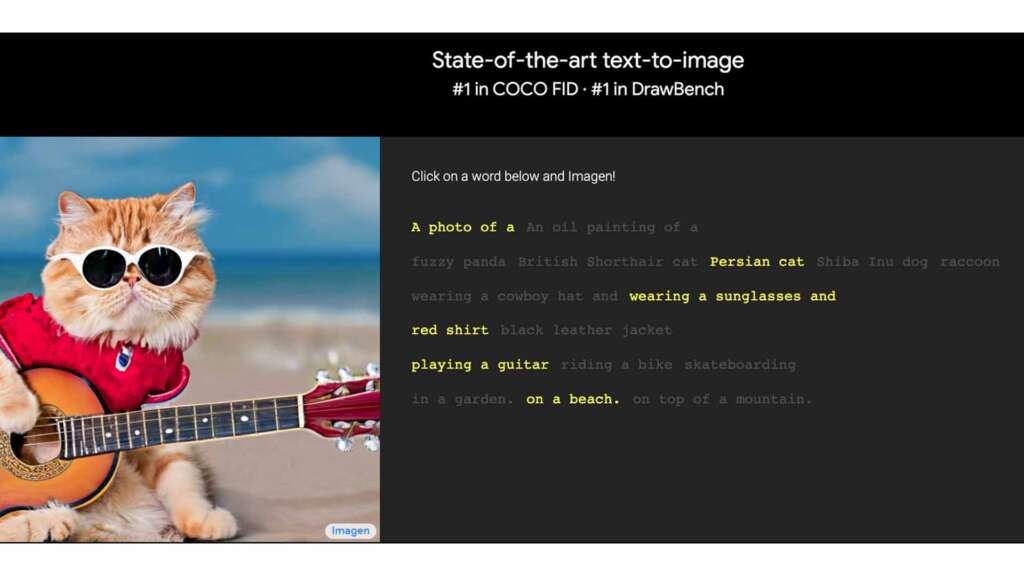
Google 利用 DrawBench 圖像模型基準測試,評估 Imagen 的文字生成圖像能力。結果顯示,比較 VQ-GAN、LDM 及 DALL-E 2 等不同類型工具,Imagen 生成的圖像逼真度更高,語言理解能力更好,亦較符合輸入的文字,偏好率更高達 50%。簡單而言,DALL-E 2 容易混淆多個顏色指令的文字,相反 Imagen 則能準確地為圖像配色。
Imagen 發展與挑戰
1. 社會影響
Imagen 與其他文字生成圖像系統一樣,都存有被誤用的潛在風險,所以社會各界都有要求開發商提供負責任的原始碼的聲音
2. 嚴重依賴數據庫
目前市場上文字生成圖像模型對數據的要求,導致研究人員過份依賴大型、大部分未經整理的、網路抓取的數據集。縱使近年演算法快速進步,但這種性質的數據庫往往帶有社會刻板印象、壓迫性觀點、對邊緣群體有所貶損等「有毒」資訊。